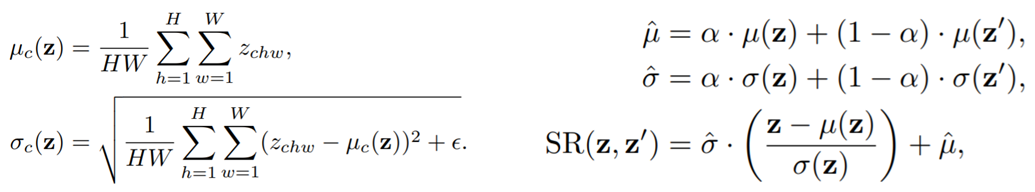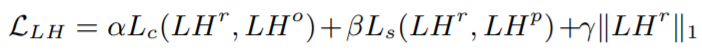이 논문은 기존의 CNN이 bias를 갖고 있다고 말하면서 시작된다. classification task에서 사람들은 보통 무늬나 텍스쳐보다는 모양을 위주로 보고 판단한다면, CNN은 모양, 즉 contents보다는 무늬나 texture를 위주로 보고 classification하는 bias가 존재한다고 한다.
이 논문의 contribution은 contents를 위주로 학습하는 네트워크와 style을 위주로 학습하는 네트워크를 구축함으로써 style bias 즉 domain bias를 줄인 CNN을 만들었다는 것에 있다.
input x와 random하게 뽑은 x'으로부터 contents biased network Gc는 x의 content, x'의 style을 가진 feature를 받아 contents만 보고 classification을 진행하게 되고, style biased network Gs는 x'의 random한 contents와 input x의 style이 합쳐져 style만 보고 classification을 하게 된다.
Content-biased Learning
contents biased network는 style을 blending시킴으로써 contents만 보고 판단하도록 만든다. z, z'은 feature extractor Gf의 output이며 각각 x, x'을 넣은 결과이다. z와 z'의 mean, std를 random한 숫자 alpha를 통해 interpolation하여 새로운 mean^, std^을 만든다. 그 후 z의 mean와 std를 mean^, std^로 변경시켜주어 contents는 동일하나 style이 달라진 feature로 만든다.
이 점에서 주의할 점은 이 논문에서는 feature의 style은 mean와 std라는 가정 하에 진행되고 있다는 것이다. style transfer, instance normalization과 같은 선행연구들을 보았을 때 mean과 std가 어느정도 style에 연관이 있다는 사실은 자명하나 mean과 std가 가장 좋은 파라미터라고 말할 수는 없다. feature의 correlation을 계산하는 gram matrice도 style을 나타내는 파라미터라고 볼 수 있다. 무엇이 가장 옵피멀한 방법인지는 모르겠다. 이부분에 대해서는 더욱 연구되어야 할 부분인 것 같다.
그 후 style이 randomization된 contents biased output에 대한 loss를 Gf, Gc에 update 한다.
Adversarial Style-biased Learning
위의 contents biased learning에서와는 달리 interpolation을 진행하지 않은 상태로 z의 mean과 std로 z'의 pdf를 변경시킨다. 이렇게 되면 z'의 random한 contents는 가지고 있는 상태로 style을 대변하는 z의 mean과 std가 합쳐진 상태가 된다.
z의 style만을 가지고 classification을 판단하는 위의 loss를 기반으로 Gs를 update해준다.
우리는 style에 bias가 적은 network를 만드는 것이 목적이기 때문에 style만을 보고 판단하는 Gs로부터 cross entropy가 maximize되는 방향으로 Gf를 업데이트 해준다. (yk대신 1/K를 곱해준 것의 의미) 이 때 Gf의 모든 parameter를 업데이트하는 것이 아닌 affine transformation parameter(batch normalization parameter)만을 업데이트한다.
Pseudo Code
Results
논문을 보면 다양한 관점에서 test가 진행되었다. 위의 test는 texture/Shape bias에 관한 실험으로, Gf에 업데이트되는 adversarial loss를 조절하는 adversarial weight를 높일수록 texture 학습은 낮아지고, shape 학습은 높아지는 경향성을 보였다. 또한 같은 class 내의 A-distance또한 줄어들었음을 확인했다.
Domain Generation 에 관련된 많은 dataset을 가지고 실험한 결과, AlexNet, ResNet18 backbone모두에서 sagnet의 training 방식을 사용했을 시 평균 정확도가 높아짐을 볼 수 있었다.
위 결과는 Unsupervised Domain Adaptation에 적용한 것으로 Office-Home dataset과 DomainNet dataset에서 모두 classification accuracy가 1-3정도 높아지는 것을 확인하였다.
이번 포스트에서는 Style Transfer의 기초가 되는 Image Style Transfer Using Convolutional Neural Networks에 대해 간단하게 소개하려고 한다. 또한 그 성능을 올리는 Instance Normalization: The Missing Ingredient for Fast Stylization 도 함께 소개하려고 한다.
-Deep Image Representations
이미지 정보를 보여주기 위하여 각기 다른 layer로부터 content image와 style image를 시각화 해보았다. Content Reconstructions 에서 초기의 layer는 디테일한 픽셀 정보들을 담고있지만 레이어가 깊어질수록 디테일한 정보를 잃었다. Style Reconstructions에서는 다른 feature들간의 correlations를 계산해 style reconstruction에 사용된다(Gram Matrices). 이는 style image의 컨탠츠는 잃고 스타일만을 복원한다는 특징이 있다.
Style Transfer
Style transfer를 위해서는 contents, style을 담당하는 두 이미지와 Pretrained vgg19, 이미지를 만들어낼 generator model이 사용된다. 두 content image, style image가 pretrained vgg19를 통과할 때 얻은 feature를 적절히 섞어서 contents와 style을 섞는 것을 목표로 한다. 왼쪽의 style image로부터는 거의 모든 layer에서 feature를 뽑으며 content image에서는 네번째 layer에서 feature를 뽑아 generator networks에 loss를 취함으로써 이미지를 만들게 된다.
contents loss는 pretrained vgg와 generator 사이에서 나온 feature 사이의 l2 loss이며, style loss는 feature에 gram matrices 취한 결과의 l2 loss라고 간단하게 생각할 수 있다.
- Instance Normalization
generator로부터 생성된 stylized image의 contrast는 style image의 contrast를 따르게 되기에 content loss를 구할 때 content image의 contrast가 style image의 contrast와 다를 경우 content loss를 optimize하기 힘들어 진다는 문제가 있다. 위의 그림을 보면 conent image의 contrast가 낮아지니 stylized image가 전보다 뭉개지는 것을 볼 수 있다.
따라서 image의 contrast를 비슷하게 조절하기 위하여 batch normalization 대신 batch 내에서 공유되지 않고 각 이미지에 대해 개별적으로 normalization하는 instance normalization을 사용하면 style transfer에 더욱 도움이 된다. 현재 CycleGAN에서 generator에서도 batch normalization 대신 instance normalization을 이용한다.
-Results
다시 style transfer 논문으로 돌아와 결과 이미지를 보면, contents는 어느정도 유지가 되며 원하는 스타일이 이미지에 입혀지는 것을 볼 수 있다.
2020년 NeurIPS에 올라온 논문으로 Do Adversarially Robust ImageNet Models Transfer Better? 이라는 논문을 리뷰해 보려고 한다. Transfer Learning을 더 target task에 잘 맞도록 개선한 것으로 adversarial robustness를 강하게 만든다.
What is Transfer Learning?
transfer learning은 이미지넷과 같은 스탠다드한 데이터셋으로 pre-trained된 모델의 학습된 weight를 가져와 이미 모델이 갖고 있는 지식을 다른 task에 활용하는 학습방식을 말한다. 학습하고자 하는 데이터가 적을 경우 pre-trained된 모델을 사용하여 transfer learning하는 방법이 유용하게 쓰인다. 저자는 transfer learning을 두가지로 나눈다.
fixed-feature transfer learning
앞의 weight는 고정하고 뒤의 classification layer만 다시 학습시키는 방법이다.
full network transfer learning
initial weight만 가져오고 모두 fine-tuning하는 학습 방법이다.
Factors that affect transfer learning performance
transfer learning performance를 좌우하는 factor로는 pre-trained model의 accuracy가 알려져 있다. pre-trained model의 accuracy가 좋을수록 그 pre-trained model을 사용하는 transfer learning 성능이 좋아진다고 한다.
그런데, 이 논문에서는 transfer learning의 성능을 pre-trained model의 accuracy만 좌우하는 것은 아니며, 또 다른 factor로 adversarial robustness를 언급한다.
Adversarial Robustness
Adversarial Robustness를 알기 위해서는 adversarial attack을 먼저 설명하면 좋을 것 같다. 위 그림과 같이 사람의 눈으로 구분이 안되는 노이지를 이미지에 추가했을 뿐인데, 사람은 이를 여전히 "pig"라고 인지하지만 모델이 "airliner"라고 잘못 판단하게 된다. 이렇게 인지되지 않는 차이를 주어 모델이 잘못 판단하게 만드는 것을 adversarial attack이라고 한다. 여기서 파생되는 Adversarial robustness는 미세한 변화에도 모델이 올바른 판단을 내리는 정도를 말한다.
adversarial robustness를 수식적으로 잠깐 보자. 기존의 loss 식을 보면 weight theta에 대하여 x, y의 loss를 줄이는 방향으로 학습이 되었다면,
Empirical risk minimization objective (ERM)
adversarial robustness를 높이기 위하여 x에 입실론보다 작은 노이즈를 추가한 x'과 y의 최대 loss를 minimize하는 방향으로 학습되게 한다. 즉, worst-case loss를 minimize한다고 말할 수 있다.
Robust risk minimization objective
위의 식에서 d는 arbitrary norm (ex. Euclidean norm)을 뜻하며, epsilon은 desired robustness에 따라 조절 가능하다. epsilon이 0일 때는 위의 ERM과 동일한 경우가 된다. 따라서 objective function의 변화는 다음과 같다.
Should adversarial robustness help fixed-feature transfer?
논문에서는 adversarial robustness를 높이면 transfer learning이 더 잘 될것이냐에 대해 두가지의 가설을 소개한다. 하나는 이전부터 만연했던 가설로, adversarially robust model은 source data에 대해 accuracy가 떨어지기 때문에 transfer performance도 떨어질 것이라는 가설이다.
두번째 가설은 저자의 주장으로, adversarial robustness가 높아지면 standard accuracy는 떨어질 수 있으나, feature respresentation이 높아져 transfer performance가 올라갈 것이라는 가설이다.
실제로 standard transfer learning과 robust transfer learning의 feature를 추출해보니 일반 모델보다 더 시각적인 정보를 더 많이 담고 있었다. 위 이미지의 (a) Perceptually aligned gradients를 보면 standard한 방식보다 robust한 방식에서 더 해석 가능하고 그럴듯한 이미지가 추출된 것을 볼 수 있다.
Experiments
Fixed Feature Transfer Learning
이 논문에서는 12가지의 다른 dataset에 대하여 transfer accuracy를 측정했다. 앞단의 weight를 고정하고 classification layer만 다시 학습하는 fixed feature transfer learning에서는 대부분 파란색 막대의 robust한 경우가 더 높게 나왔음을 볼 수 있다.
Full Network transfer learning
네트워크의 initial weight만 가져오고 모두 fine-tuning하는 full network transfer learning에서는 12가지의 데이터셋에 대하여 대부분 앞의 fixed-feature transfer learning보다 좋은 결과를 가져왔다. 또한 standard보다 robust learning의 방식에서 마찬가지로 transfer accuracy가 높아지는 것을 볼 수 있었다.
Object Detection and Instance Segmentation
Classification 뿐만 아니라 다른 Computer Vision Task인 Object Detection, Instance Segmentation에서도 ImageNet을 기반의 pre-trained model을 robust transfer learning으로 사용할 때 더 좋은 정확도를 달성할 수 있었다.
ImageNet Accuracy and Transfer Performance
앞서 말했던 transfer performance에 영향을 미치는 standard accuracy와 robustness는 자칫하면 trade-off 관계라고 생각될 수 있다. 그러나 저자는 둘을 동시에 변인으로 두고 관찰하는 것이 아니라, 하나를 고정시킨 후 transfer performance를 관찰해야 한다고 말한다.
즉, robustness를 고정하였을 때, 더 높은 standard accuracy는 transfer learning performance를 증가시킨다. 또한 standard accruacy가 고정됐을 때, 더 높은 robustness는 transfer learning performance를 증가시킨다.
따라서 epsilon이 0과 3인 두 경우에 대해 performance가 다른 A~F의 모델에 대해 transfer learning을 진행한다. 이 경우 epsilon을 고정하고 모델들을 바꿨으므로 robustness를 고정하고 standard accuracy에 차이를 둔다고 볼 수 있다.
실험 결과, 기존의 논문들에서 주장된 것과 같이 standard accuracy가 높을수록, 즉 F에서 A로 갈수록 transfer accuracy또한 높아지는 것을 볼 수 있었다.
그러나 robustness를 fix하지 않고 epsilon을 변화시켰을 때 standard accuracy인 ImageNet Accuracy와 Transfer Accuracy의 linear한 성질이 깨지는 것을 위의 그래프에서 볼 수 있다. 여기서 특히 CIFAR 데이터셋같은 경우는 standard accuracy가 높을수록 transfer accuracy는 낮아져버리는 아예 상반되는 결과를 보여준다.
다른 데이터셋과 다른 CIFAR 데이터셋의 특징을 고려해봤을 때, 이미지의 resolution을 들 수 있다. CIFAR는 32x32의 작은 이미지 사이즈를 갖고 있으며 다른 데이터셋들은 더 좋은 이미지 resolution을 갖는다. 따라서 다른 데이터셋도 CIFAR의 resolution과 동일하게 해주기 위해 32x32로 downscaling하여 실험을 진행하였다.
그 결과, 모두 ImageNet Accuracy가 높아질수록 Transfer Accuracy가 낮아지는 결과를 보였다. 이 결과를 해석해보자면, 이미지의 resolution, 즉 정보량이 적을 때 robustness를 증가시키는게 transfer learning performance에 더욱 중요해진다는 의미가 될 수 있다.
Comparing Adversarial Robustness to Texture Robustness
또 다른 실험으로, Stylized ImageNet(SIN)을 활용한 실험이다. 2019년 CVPR에서 발표된 논문중에 CNN이 contents가 아닌 texture에 더 집중해서 학습한다는 논문이 발표된 바가 있는데, 이런 선행연구를 기반으로 texture robustness과 adversarial robustness를 비교했다.
그 결과 texture-invariant model를 이용해 transfer learning을 진행한 모델보다 adversarially robust model이 더 좋은 성능을 보였다.
Conclusion
이 논문을 정리하자면, adversarial robust neural network가 기존의 transfer learning보다 standard accuracy는 떨어트리지만, targe accuracy에 대해서 더 좋은 성능을 보였으며, 그 이유에 대해서는 future work로 남겨두고 있다.
먼저 cyclegan을 이용해 source domain을 target domain으로 domain adaptation을 진행하고 target domain으로 스타일이 바뀐 source data로 segmentation 네트워크를 학습하여 실제 target domain에서의 성능을 높이는 방법이다.
2. target domain으로 옮겨진 source data'을 이용하여 segmentation 네트워크 학습시키기 (deeplab)
이런 2 step domain adaptation은 사실 이전에도 여러번 소개가 되었다.
Dual Channel-wise Alignment Networks for Unsupervised Scene Adaptation(DCAN) 이나 cyCADA 논문도 위와 같은 형식이라고 알고 있다.
그런데 이렇게 2 step으로 네트워크를 학습시킬 때 발생하는 문제점이 있다. 첫번째 step에서 Image Generator의 성능이 떨어진다면, 두번째 step에서의 성능이 결코 좋을 수 없다는 것이다. 즉, segmentation network의 성능이 image generator의 성능에 의해 한계점을 지니게 된다.
본 논문에서는 위와 같은 한계점을 보완하는 방법을 제시한다.
Contribution
논문에 제시되어 있는 자신의 논문의 기여는 다음과 같다고 한다.
"""
1. Bidirectional Learning System, which is a closed-loop to learn the segmentation adaptation model and the image translation model and the image translation model alternatively
2. Self-supervised learning algorithm for the segmentation adaptation model, which incrementally align the source domain and the target domain at the feature level, based on the translated results
3. New Perceptual loss to the image-to-image translation, which supervised the translation by the segmentation adaptation model
"""
1. 2step을 개별적인 단계가 아닌 유기적으로 이어지게 (closed-loop) 만듦으로써 앞뒤 스텝의 단점을 상호 보완 가능하게끔 만들었으며,
2. 두번째 스텝에서 self-supervised learning algorithm을 추가하였고,
3. 첫번째 스탭에서 두번째 스텝 네트워크를 활용한 perceptual loss를 추가하여 segmentation adaptation model로부터 training에 필요한 정보를 얻었다고 한다.
Model
전체 네트워크는 위와 같다.
Image Translation Model을 통해 source data를 target domain으로 shift 한 후, 그 shift된 source data를 Segmentation Adaptation Model을 학습하여 결과를 얻는다. 그런데 Image Translation Model에서 Segmentation Adaptation Model 아웃풋을 이용한 loss인 perceptual loss가 추가된다. Segmentation Adaptation Model에서는 adversarial loss가 존재하고, 스스로 mask를 만들어 self-supervised learning을 진행한다고 하는데... 자세한 내용은 loss를 천천히 뜯어보면 알 수 있겠다.
Loss
loss들을 같이 보기 전, 기억해야할 notation은 다음과 같다.
source data = S
target data = T
translated source data by forward cyclegan = S'
translated target data by inverse cyclegan = T'
Image Translation Model (cyclegan generator) = F
cyclegan inverse generator = F-1
Segmentation Adaptation Model = M
첫번째 스텝인 image translation model로 cyclegan을 활용하였으며,
그 loss는
image translation model loss
이다. 람다 GAN은 1, 람다 recon은 10 을 사용했다고 한다.
하나하나 뜯어보자. 첫번째로 GAN loss이다.
image translation model loss - GAN loss
S'과 T의 domain을 구분하지 못하도록. 또는 S와 T'의 domain을 구분하지 못하도록 만드는 loss이다. discriminator는 S'을 0으로, T 를 1로 구분하도록 학습하였으니, 반대로 generator는 S'을 1로, T를 0으로 라벨하여 loss를 얻는 것을 볼 수 있다.
image translation model loss - Reconstruction loss
F를 통과하여 만들어진 S'을 다시 F-1 함수에 통과하였을 때, S로 되돌아오는지, reconstruction 되는지 확인하는 pixel-level loss이다. L1 loss를 사용하고 있다. cyclegan 논무에 따르면, 이 loss를 추가함으로써 generator F가 다시 되돌릴 수 있을 만큼만 이미지를 바꿔주어 이미지의 content를 보존할 수 있었다고 한다.
image translation model loss - perceptual loss
논문의 핵심 특징 중 하나인 perceptual loss이다. 두번째 step의 segmentation model과 연결시켜주는 고리이기도 하다. segmentation adaptation model M을 마치 perceptual loss의 VGG 네트워크처럼 활용하여 S와 S'의 perceptuality, 그리고 F-1(S')과 S의 perceptuality를 줄이는 방향으로 학습한다. 람다 per은 0.1, 람다 per_recon은 10이다. 이러한 perceptual loss를 추가함으로써 segmentation adaptation model M이 가지고 있는 domain bias를 image translation model에서 보완해 줄 수 있게 된다.
두번째 스텝인 segmentation adaptation model로 deeplab v2를 사용하였으며,
그 loss는 self-sueprvised loss의 유무로 두가지 종류가 존재한다.
segmentation adaptation model loss without self-supervised loss
segmentation adaptation model loss with self-supervised loss
람다adv는 0.001이다.
이번에도 하나하나 뜯어보자.
segmentation adaptation model loss - adversarial loss
먼저 위 논문의 큰 특징 중 하나인 adversarial loss이다. image translation model 뿐만이 아닌 segmentation model에도 adversarial loss를 추가함으로써 image translation model에서 미처 줄이지 못한 source와 target 사이의 거리를 줄이는 방향으로 보완해 준다.
segmentation adaptation model loss - segmentation loss
segmenatation model에서 항상 등장하는 cross entropy loss이다. domain shift 된 S'을 input으로 하여 얻은 M(S') 결과값과 segmentation label Ys 사이의 loss를 계산한다.
segmentation adaptation model loss - self-supervised segmentation loss
마지막으로 핵심 loss인 self-supervised segmentation loss이다. target data label이 주어지지 않았을 때, 스스로 라벨을 형성하여 unsupervised learning을 진행한다.
학습이 덜 된 네트워크에서 나온 결과값을 정답값이라고 가정한다는 것이 아이러닉하게 들릴 수도 있겠다. 그러나, segmentation task의 특징을 잘 생각해 보자. 도로를 segmentation한다고 했을 때, 도로의 정 중앙이 도로에 속한다는 것은 쉽게 알 수 있지만, 도로의 가장자리, 즉 나무 또는 보도와 가까운 pixel일수록 도로인지 아닌지 판단하는 것은 어려워진다. 즉, 같은 segmentation task에서도 pixel마다 쉽게 class를 판단 가능한지 아닌지 난이도의 차이가 존재하기에 확률의 차이가 존재하게 된다.
따라서 높은 확률로 판단 가능한 쉬운 pixel에 대해서 우리는 sudo label을 만들 수 있다. 몇퍼센트의 확률로 class를 확신하면 sudo label로 설정할 것이지에 대한 threshold는 0.9로 정했다고 한다. 이렇게 정해진 threshold로 우리는 target data에 대한 sudo label을 구할 수 있고, 이 sudo label을 논문에서는 mask라고 부른다. figure 3에서 예시로 주어진 mask를 살펴보면 구분선은 검정색(0)으로 구분하기 어려운 곳이기 때문에 sudo label을 형성하지 못한것을 볼 수 있고, 특정 class의 내부는 흰색(1)로 구분하기 쉬웠기 때문에 sudo label이 형성되었음을 볼 수 있다. 이렇게 정해진 sudo label에 대해서만 target segmentation loss를 구하여, training을 더욱 가속화한다.
Training Process
이렇게 정의된 2 step network를 구성하는 F,M model은 다음과 같은 프로세스로 training이 진행된다.
training process
먼저 일반 segmentation model과도 같은 M(0)를 학습시킨다. 위의 M을 training 하는 loss에서 adversarial loss와 self-supervised segmentation loss를 제외한 segmentation loss만을 활용한 것을 말한다.
이번 방학에는 domain adaptation 논문들을 정리하여 리뷰해 보려고 한다. 심심할 때 리눅스 쉘에서 자주 쓴 명령어도 정리해 기록해 보고자 한다.
지금 2020년도 기준으로 이번에 리뷰하는 [Domain Adversarial Training of Neural Networks] 논문은 어찌 보면 상당히 올드하다. 이보다 더 좋은 많은 알고리즘들이 쏟아져 나오고 있지만, 그럼에도 불구하고 Domain Adaptive에 가장 기본적인 성질을 담고 있으며, 이를 수식적으로 잘 설명한 논문이니 Domain Adaptation 카테고리에서 첫 번째로 리뷰해 본다.
먼저 domain adaptation이란 무엇인지 간단히 짚고 넘어가 보자. domain adaptation이란 간단히 말해서 위와같이 잡지에서 찍은 것과 같은 SVHN 숫자 dataset에서 training 시킨 네트워크로 전혀 다른 style을 갖는 MNIST 숫자 dataset을 분류하는 데에 쓰고 싶을 때 두 domain의 간격을 줄여주는 방법이다. 우리는 이렇게 네트워크를 training 할 때 쓰인 dataset을 source dataset, 그 도메인을 source domain이라고 칭한다. 또한 source로 training 시킨 네트워크로 분류하고자 하는 test set을 target dataset이라고 하며, 그 도메인을 target domain이라고 한다.
간단한 문제에서는 source domain 하나, target domain 하나가 주어진다. 더 고차원적인 문제를 생각해 본다면, source에 한가지의 domain이 있는 것뿐만이 아닌 여러 가지의 다양한 domain이 source domain으로 주어질 수 있다. 위 그림처럼 같은 숫자를 담고 있지만 그 숫자의 굵기나 색깔, 배경, 폰트가 다름으로써 다양한 domain의 숫자 dataset이 주어질 수 있다. 우리는 이를 [multi source domain adaptation]이라고 부른다. target domain이 여러 가지인 경우도 마찬가지로 [multi target domain adaptation]이라고 부른다.
이런 domain adaptation은 transfer learning의 일종으로 분류된다. source와 target 데이터셋의 distribution이 다르지만, 두 도메인에 같은 task를 적용할 때 이를 Transductive Transfer Learning이라고 부르며, 이 해결 방식으로 Domain Adaptation이 제시되었다.
그럼 이제 진짜로 논문리뷰를 시작해 보겠다. 2020-07-25 기준으로 본 논문은 2000회에 육박하는 높은 인용수를 보인다.
먼저 DANN(Domain Adversarial Neural Net)의 네트워크 구조를 보고 넘어가자. DANN은 classification에서 class label을 구분하는 task와 source와 target의 domain을 구분하는 두 task를 동시에 진행한다. 네트워크 앞부분은 서로 공유하며, 앞 네트워크에서 뽑은 feature로부터 class label을 구분하는 보라색 네트워크와 input으로 들어온 사진이 source인지 target인지 구분하는 분홍색 네트워크로 구성되어있다. 이때 우리의 목표는 앞의 feature extractor Gf가 최대한 source와 target에 동시에 포함되는, domain의 특성을 지우고 class 분류에만 쓰인 특징을 뽑게 하는 것이다. 이를 위하여 back propogation시 domain label을 구분하는 분홍색 네트워크에서 뽑힌 loss에 -람다를 곱해 feature extractor weight를 업데이트한다. 이렇게 되면
MInimize Training classification error
Maximize Training & test domain classification error
두 목적을 동시에 달성할 수 있게 된다.
위와 같은 방식으로 정말 domain간의 거리를 줄일 수 있는가?라는 의문이 들 수 있을 것이다. 위 논문에서는 실제로 줄어든다는 것을 수식적으로 증명한다.
그런데, 두 dataset의 domain 분포 거리를 줄이려면, 두 domain 거리를 측정할 수 있어야 할 것이다. 두 domain 사이의 거리를 측정하는 방식은 Domain Divergence를 측정함으로써 계산할 수 있다.
우리의 목적을 한번 더 말하자면, target domain error를 줄이는 것이다. target domain error는 source domain error + domain divergence로 upper bound를 정할 수 있다. 즉, source domain에서 classify를 잘하고, source domain과 target domain과의 거리가 가깝다면, target error가 작을 것이다.
Ben David는 domain divergence를 위와 같이 정의한다. 여러 domain classifier 이타를 원소로 하는 classifier 집합을 hypothesis class H 라고 정의했을 때, H-divergence란 두 도메인을 잘 구분하는 classifier를 얼마나 담을 수 있는지를 뜻하기에 도메인을 구분하는 능력을 칭한다. 실제로 거리의 개념은 아니지만 두 도메인 사이의 거리와 같은 말이라 생각해도 괜찮다.(말은 통한다)
H divergence는 'source domain을 1로 판단할 확률 - target domain을 1로 판단할 확률'이라고 정의되어 있다. 이해를 돕기 위해 간단히 예시를 들어보자면, classifier가 두 도메인을 구분하지 못할 때 위 식은 1/2 -1/2가 되어 0이 되며, 두 도메인을 잘 구분할 때 1-0 또는 0-1이 되어 그 절댓값은 1로 divergence가 커지게 된다.
그 밑에 나온 수식까지 함께 봐보자. 위의 식은 true divergence이며 밑의 식은 이를 정말로 구할 수 있게 modify한 empirical H-divergence이다. 위의 식으로부터 밑의 식을 얻기 위해서는
확률 Pr을 sigma * 1/n 으로 바꿔 계산 가능하게끔 만든다.
'source domain을 1로 판단할 확률' = '1 - source domain을 0으로 판단할 확률' 이므로 위의 식의 앞 Pr 부분을 치환해 준다.
이렇게 하면 empirical H-divergence를 구할 수 있다.
empirical H-divergence 식의 이해를 돕기 위해 좀 더 설명하자면, 먼저 I [ ]는 indicator function으로 true면 1을, false면 0을 뱉는다. min term 내부를 보면, domain classifier 이타가 domain을 잘 분리했을 때 1+1이 된다. 근데, 이 이타가 존재하는 공간은 symmetric hypothesis class이므로, 1+1이 존재하면 0+0도 존재하게 된다. (마치 100점 맞는 친구는 0점도 맞을 수 있다는 의미이다) 두 값중 min값이 선택되면 0+0이 선택되게 된다. 만약 domain classifier 이타가 domain을 잘 분리하지 못한다면 1/2+1/2가 된다.
따라서 min term은 잘 분리하면 할수록 0(0+0)에 가까운 숫자가 되고, 잘 구분하지 못할수록 1(1/2+1/2)에 가까워진다. 잘 구분하지 못할수록 숫자가 커지게 되니 이는 마치 loss 값과 같다고 할 수 있다. 그래서 이 min term은 domain classifier의 loss값으로 대체 가능하다.
min term은 domain classifier error인 입실론으로 대체되며, 이때의 H-divergence를 Proxy Distance, Proxy-A-distance(PAD)라고 부른다. 보통 이 domain classifier로 간단한 MLP나 linear SVM을 많이 사용한다.
직관적인 이해를 돕기위해 다시 예시를 들어보자면, domain loss가 작을 때, PAD는 커지게 되며, 이는 source와 target domain 거리가 멀어 구분이 쉽다는 것이다. 반면 domain loss가 클 때 PAD는 작아지게 되며, 이는 source와 target의 distribution이 비슷해 구분이 어렵다는 뜻으로 해석 가능하다.
지금까지의 과정을 되짚고 넘어가보자.
Target error <= source error + H-divergence
이며, H-divergence를 구하기 위해 empirical H-divergence를 구해봤다. 그런데 사실 true H-divergence와 empirical H-divergence는 완전히 동일할 수 없다.
true H-divergence의 upper bound가 empirical-H-divergence + H-complexity 로 measure 된다. 즉, 우리가 경험적으로 구한 empirical H-divergence에 그 classifier의 복잡도를 더한 값이 실제 H-divergence의 upper bound가 된다. 이는 overfitting과도 관련이 있는데, classifier가 train dataset에 맞춰 꼬불꼬불한 구분선을 갖게 된다면, 이는 train dataset에 overfitting 되어 valid dataset이나 test dataset에서 좋은 성능을 갖지 못한다. 이때 꼬불꼬불한 classifier는 complexity가 높다고 말할 수 있겠다. 이처럼 우리는 H의 complexity를 구해, 우리가 경험적으로 구한 H divergence가 실제로 잘 작동할 것이라는 것을 입증해야 한다.
를 수식으로 나타내면 위와 같다. 이타*는 domain을 잘 구분하는 classifier로 베타 >= inf(Rs+Rt) 식에 의해 베타는 source, target 모두에서 잘 작동하는 domain classifier 이타가 존재할 때 최소가 된다. 그런 classifier 이타가 H 안에 존재하려면(H는 classifier 이타의 집합이라고 위에 언급하였다!) H의 dimension은 충분히 커야한다. 그러나, complexity term이 존재하기에 H의 dimension은 한없이 커져서만도 안된다.
즉, 잘 구분하는 classifier 이타를 H에 포함할 수 있을 만큼 H의 complexity는 커야하지만(베타 값을 작게 하기 위하여), complexity가 너무 크다면, constant complexity의 값이 커져 결국 target error의 upper bound는 커져버리게 된다. 따라서 충분한 성능을 내는 classifier가 있어야 하나 이 classifier가 너무 복잡해서는 안 되겠다. 그래서 간단한 MLP나 SVM을 주로 쓰나 보다.
주절거리다 보니 본 논문의 핵심 아이디어는 대충 다..? 건들여 본 것 같다. 마지막으로 정리해보자면,
네트워크가 source domain에서 좋은 성능을 낼수록
source-target divergence가 작을수록
H set의 complexity가 적당히 클수록
target domain error를 minimize할 수 있다.
그럼 이만 논문 리뷰를 끝내고, 다음 포스팅부터는 2019-2020년도의 최근 논문 위주로 리뷰해 보도록 하겠다!
이번 포스팅에서는 2019년 ICCV에서 발표된 wavelet style transfer 이용한 super-resolution 논문을 리뷰해 보려 한다.
0 Abstract 부터 2 Related work는 배경설명 및 다른 네트워크들간의 비교이며 본 논문의 모델은 3 proposed method에서 소개한다.
<간단 요약>
1. EDSR, CX를 이용하여 성질이 다른 두 이미지를 얻는다.
2. 두 이미지를 stationary wavelet transform(SWT)을 통해 low frequency sub domain과 high frequency sub domain을 구분한다.
3. high frequency sub domain를 pixel domain이 아닌 wavelet domain에서 style transfer를 함으로써 high frequency perceptuality를 개선하였다.
4. EDSR의 low frequency sub domain을 압축된 VDSR에 통과시켜 objective quality를 높였다.
5. content loss와 style loss 모두를 고려하는 새로운 loss function을 제안했다.
6. 그 결과 high frequency detail이 살아났으며 선명한 텍스쳐와 구조를 얻을 수 있었다. 즉, PSNR과 NRQM(perceptuality)를 모두 높일 수 있었다.
0 Abstract
super-resolution은 LR(low-resolution, 저해상도) 이미지로부터 HR(high-resolution, 고해상도) 이미지를 복원하는 것을 말한다. 최근 super-resolution 부문의 이슈는 low distortion과 high perceptual quality가 trade-off 관계라 두 관점을 모두 만족시키기 어렵다는 것이다.
지난번에 언급한 SRCNN, VDSR, EDSR 등의 논문들은 모두 LR이 HR에 최대한 가까워 지도록 학습해 distortion은 적지만(PSNR은 높지만) 엣지가 선명하지 않고 디테일이 사라지며 질감이 무너지는 것과 같이 사람의 눈으로 보았을 때 만족스럽지 않은(low perceptual quality) 결과를 얻었다.
이런 low perceptual quality 문제점을 최근 GAN 을 기반으로 한 모델이 photo realistic한 이미지를 만들어 내며 잘 보완해 주고 있다. 그러나 이 논문에서는 wavelet domain style transfer(WDST)를 이용하여 GAN을 기반으로 한 모델보다 perception-distortion(PD) trade-off 를 더 잘 보완할 수 있었다고 한다.
2D stationary wavelet transform(SWT)를 이용하여 이미지의 low-frequency 부분과 high frequency 부분을 나눠 각각에 대해 독립적으로 개선시킨 후 합친다는 것이 이 논문의 취지이다. low-frequency sub-bands를 이용하여 objective quality를 개선하고(low distortion), high-frequency sub-bands를 이용하여 perceptual quality를 개선할 수 있다.
1 Introduction & 2 Related work
앞서 말했듯이 기존의 연구는 mean square error(MSE)를 낮춰 objective image quality를 높이는 데 집중한 연구와 adversarial training을 통해 perceptual loss를 낮춰 perceptual image quality를 높이는 데 집중한 연구로 나뉜다. 아래의 그림1을 보면 PSNR을 높이는 데 집중한 파란색 네트워크들과 perceptuality(NRQM metric)를 높인 초록색 네트워크들이 명확히 구분된다.
objective quality를 높인 그림1의 파란색 네트워크들은 대부분 MSE를 minimize하여 reconstructed image와 ground truth image 사이의 간극을 좁힌다. 이는 high frequency detail들이 사라져 엣지가 blur된다는 문제점을 야기한다.
perceptual quality를 높인 그림1의 초록색 네트워크들은 VGG loss와 adversarial loss의 weighted sum으로 구성된 perceptual loss를 낮추도록 학습한다. VGG loss는 reconstructed image와 ground truth image 간의 perceptual similarity를 높이는 데 효과적이며, adversarial loss는 reconstructed image를 realistic하게 만든다.
그림1. PSNR과 NRQM의 trade-off 관계 속 PSNR에 집중한 네트워크(파랑)와 perceptuality에 집중한 네트워크(초록)와 절충점을 찾는 네트워크(주황)
위 trade-off 관계를 보완하기 위하여 adversarial loss와 MSE를 활용하는 SRGAN-MSE, ENet등의 그림1의 주황색 모델이 도입되었으나 unstable하다는 지적이 있었다. SRGAN-MSE는 MSE loss와 adversarial loss를 합쳐 사용하는데, adversarial loss는 결과 이미지의 high frequency detail들을 살려냈지만, 그것이 정확한 위치에 있지 않아서(ground truth image와는 사뭇 다른 이미지여서) MSE distortion은 증가되는 문제점이 있었다. 이런 instability 문제점을 보완하기 위해 texture matching loss를 도입하였지만 여전히 blocking과 noisy artifact가 생겼다.
원치 않는 artifact들이 생기는 문제점을 보완하기 위하여 ESRGAN이 등장하였다. PIRM challenge에서 우승한 ESRGAN은 MSE를 낮추는 프로세스와 perceptual quality를 높이는 프로세스를 분리하기 시작한다. 두개의 독립적인 네트워크는 마지막에 interpolation하여 합쳐진다. 그러나 network interpolation은 두 네트워크가 완전히 똑같은 구조를 가지고 있어야 하기에, 분명히 다른 성질을 갖고있는 두 부분에 대해 각각의 성장 가능성을 저해한다는 단점이 있다.
따라서 network interpolation이 아닌 분리된 네트워크에서 나온 image들의 fusion을 고안해 보았을 때, 네트워크 구조의 유연함을 증폭할 수 있다는 점이 큰 장점이다. 최근 Deng 이 style transfer를 이용한 두 이미지의 fusion을 제시하였다. 그러나 style transfer는 pixel domain상에서의 작업이므로 이미지의 structure와 texture를 동시에 보존한다는 것은 매우 까다롭다. 그림2를 보면 objective and perceptual quality 의 trade-off관계 속에서 optimize를 시도하였으나 여전히 발전이 필요해 보인다.
그림2. 네트워크 결과 비교
본 논문에서는 pixel domain이 아닌 frequency domain에서 low-frequency와 high-frequency로 분리함으로써 Deng의 부족한 점을 보완할 수 있었다. 새로운 SISR(single image super-resolution) method를 선보이는 것은 아니나, 기존의 성질이 다른 두 네트워크를 사용하여 얻은 두 결과 이미지를 fusion함으로써 best tradeoff를 찾았다는 것에 의의가 있다.
본 논문을 SRGAN-MSE 논문과 비교하였을 때 deep network를 train하지 않아 stability 걱정이 없으며, ESRGAN과 비교하였을 때 네트워크 구조가 훨씬 flexible하고, Deng과 비교하였을 때 wavelet domain에서의 style transfer를 구현하여 새로운 테크닉을 선보였다는 점에서 좋은 결과를 얻을 수 있었다.
3 Proposed method
Stationary wavelet transform
기존의 discrete wavelet transform(DWT)는 shift invariant하지 않기 때문에 convolution을 적용할 수 없다. 따라서 DWT에서 downsampling operation을 제거한 stationary wavelet transform(SWT)을 적용하였다. 2D SWT는 그림3의 수식과 같이 1D wavelet decomposition인 H0(low-pass filter)과 G0(high-pass filter)의 z transform으로 얻어진다.
2D SWT 수식그림3. 2D SWT of image X with H0 and G0 as the low-pass and high-pass filters, respectively
2D SWT는 이미지를 여러개의 sub-bands로 나누는데, 이는 1개의 low-frequency sub-bands(LL)와 여러개의 high-frequency sub-bands(LH, HL, HH)로 구성된다. 2 level decomposition을 진행한 후, input X는 7개(3*2high+1low)의 상태로 나뉘어 지며 LH, HL, HH는 각각 horizontal, vertical, diagonal detail을 나타낸다. level2는 level1의 LL로부터 생성된다.
Motivation
여기서 중요한 insight는 LL을 나타내는 low-frequency sub-band가 이미지의 objective quality에, 나머지 LH, HL, HH와 같은high-frequency sub-bands가 perceptual quality에 각각 지대한 영향을 미친다는 것이다. 이를 증명하기 위해 CX로부터 얻은 high perceptual quality를 가진 Ap 이미지와 EDSR로부터 얻은 high objective quality를 가진 Ao이미지를 얻었다. Ap, Ao 이미지를 1 level decomposion하여 얻은 sub-bands를 관찰해 보자.
그림4. histograms of different sub-bands of Ap, Ao, Ground Truth
그림4를 보면, Ao의 LL sub-band histogram이 Ap의 LL보다 ground truth LL과 더욱 유사함을 볼 수 있고, Ap의 LH, HL, HH sub-bands histogram이 Ao의 LH, HL, HH보다 ground-truth의 LH, HL, HH와 더욱 분산이 유사함을 볼 수 있다.
다음으로 정량적인 분석을 해보자. 성능비교를 위해 objective quality에는 PSNR(peak signal-to-noise-ratio)를, perceptual quality에는 NRQM을 각각 평가지표로 사용하였다. (PSNR과 NRQM은 모두 높을수록 좋은 성능임을 나타낸다.)
Ao의 LL과 Ap의 LH, HL, HH를 합친 것을 Ap~, Ap의 LL과 Ao의 LH, HL, HH를 합친 것을 Ao~라고 할 때, Ap, Ap~,Ao, Ao~의 PSRN, NRQM을 출력해 보았다. 표를 보기 전, 앞서 말했던 맥락을 참고하였을 때, Ap~는 Ao의 LL을 받았으므로 Ap보다 더 좋은 objective quality를 갖고 있어야 한다. 따라서 PSNR이 높아지고 NRQM이 조금 낮아질 것을 예상할 수 있다. Ao~는 Ap의 LL을 받았으므로 Ao보다 더 좋은 perceptual quality를 갖고 있어야 하나, LL은 다른 sub-bands에 비해 perceptual 정보를 적게 갖고 있으므로 NRQM이 조금 높아지고(Ap에 못미치게) PSNR은 낮아질 것을 예상할 수 있다.
Table1
여기까지 보았을 때, 우리는 LLo가 objective quality를 높일 sub band이며, 나머지 sub band가 LHp, HLp, HHp에 가까울수록 perceptual qualiity가 높아질 것을 알 수 있다.
그림5. the framework of our method
Low-frequency sub-band enhancement (LSE)
이제 드디어네트워크의 뼈대를 살표볼 차례이다. perceptuality를 높이는 네트워크(CX)에서 얻은 아웃풋(Ap)과 objectivity를 높이는 네트워크(EDSR)에서 얻은 아웃풋(Ao)을 각각 SWT(wavelet transform)하여 frequency domain으로 분리한다.
low frequency sub band인 LLo는 objective quality를 더욱 강화하기 위한 LSE 작업을 거친다. LSE는 VDSR의 구조를 차용한 작은 네트워크로, 6개의 convolution layer와 Relu를 지나 마지막에 input을 더해 output을 출력한다. 모든 layer의 filter 는 64개, filter size는 3x3이며 loss는 l2 norm을 이용한다.
Wavelet domain Style transfer (WDST)
SWT 하여 얻은 LHo, HLo, HHo를 style transfer하여 LHp, HLp, HHp에 비슷하게 바꿈으로써 perceptual quality를 높이고자 한다. 따라서, LHp를 style input으로, LHo를 content input으로 하여 LHo의 content를 유지하며 LHp의 style을 갖는 아웃풋 LHr을 생성할 수 있도록 style transfer를 진행한다.
기존 style transfer와의 차이점은 wavelet coefficients를 input으로 넣는다는 것이다. wavelet transform한 결과는 음수도 있고 1보다 큰 숫자도 있기 때문에 VGG19 network에 input으로 넣기 전 0-1로 normalize해야한다.
수식1. style transfer loss
normalization 후 각각의 high-frequency sub-band pair에 대하여 새롭게 정의한 loss를 줄이는 방향으로 아웃풋을 만들어 낸다.loss function은 수식1에서 볼 수 있듯 content loss(Lc), style loss(Ls), l1 loss의 weighted sum으로 구성된다. l1 norm loss를 추가한 이유는 wavelet coefficients에 0 값이 많기 때문이다(그림4의 히스토그램 참고). 데이터가 sparse할 때(0값이 많을 때), l2 loss보다 l1 loss를 사용하는 것이 더 효과적인데, 다음 사이트에 설명이 잘 나와있어 첨부한다. 간단히 말하자면 l2 loss는 항상 양수인 값들이 존재하기 때문에 sparse한 상황에서 0을 향해 optimize되는 데에 한계가 있다.
수식2. content loss수식3. style loss의 weighted sum수식4. 각 층의 style loss
content loss와 style loss는 pre-trainedVGG19 네트워크를 이용하여 여러 feature를 중간에서 뽑아 loss를 계산한다(그림5의 WDST).content loss는 MSE loss로 conv2-2 에서LHo와 LHr의 feature를한번 뽑아 content loss를 계산하며 수식2의 N은 layer L의 feature map 수, M 은 feature map의 weight*height를 나타낸다.
style loss는 Relu1-1, Relu2-1, Relu3-1, Relu4-1, Relu5-1 총 5개의 층에서 LHp와 LHr의 feature를 뽑아 weighted sum하여 style loss를 계산한다(수식3). style loss는 gram matix의 MSE loss를 계산함으로써 LHr과 LHp 간의 correlation을 계산한다.
이렇게 high frequency sub-bands LHr, HLr, HHr를 얻었으면 de-normalization해주어 본래의 data 분포를 갖게끔 만들어준다. 앞서 LSE를 통해 강화된 LLr과 LHr, HLr, HHr를 합쳐 2D ISWT(inverse stationary wavelet transform)하면 결과 이미지를 얻을 수 있다.
4 Numerical Results
Experimental setup
-2D SWT의 wavelet filter로는 bior2.2를 사용
-wavelet decomposition level은 2
-SGD optimizer 사용 (LSE)
-batch size 64 (LSE)
-basic learning rate 0.01, momentum 0.9 (LSE)
-ratio between the content loss and the style loss 10^(-3) (WDST)
-ratio between the content loss and the l1 norm loss 10^(-5) (WDST)
-style loss의 각 layer weight 0.2 (WDST)
-first layer maximum iteration 5000, second layer maximum iteration 1000 (WDST)
-Ao는 EDSR을 통해 얻음
-Ap는 CX를 통해 얻음
-dataset : Set5, Set14, BSD100, Urban100, PIRM
Wavelet filter sensitivity
그림6. 다양한 필터 적용 결과
그림 7. haar, db2, bior2.2
그림7. coif2, db4
그림7. rbior2., bior4.4
본 논문에서는 7가지의 wavelet filter를 사용하여 PSNR, SSIM, NRQM을 비교하였다. 다른 wavelet function들과는 다르게 rbior2와 bior4.4는 decomposition과 reconstruction시 사용되는 wavelet function의 모양이 다르다. PSNR을 높이는 데에는 haar, db2가 효과적이었으며, NRQM을 높이는 데에는 bior4.4가 효과적이었다.
나는 여기까지 읽었을 때, "그래서 이렇게 하면 좋다는건 알겠는데, EDSR과 CX를 그냥 합친것보다 뛰어난지는 어떻게 알지?" 라는 의문이 들었다.
Content and Style inputs sensitivity
그림8. interpolation보다 우세함을 보임
그림8은 objectivity가 뛰어난 네트워크에서 뽑은 결과 Ao와 perceptuality가 뛰어난 네트워크에서 뽑은 결과 Ap의 단순 interpolation 결과와 본 논문의 방법을 비교한 것이다. PSNR과 Perceptual score모두 interpolation한 결과보다 뛰어난 성능을 보임을 알 수 있다.
드디어 논문 리뷰가 끝이 났다!! 다음에는 cycleGAN을 다뤄볼까...
REFERENCE
1. Xin Deng et al, "Wavelet Domain Style Transfer for an Effective Perception-distortion Tradeoff in Single Image Super-Resolution", 2019 ICCV
지금까지 딥러닝을 이용한 화질개선(super-resolution)에 관한 여러 논문들이 소개되어 왔다. 이 포스팅에서는 지금까지 어떤 논문들이 있었는지(2014-2018) 간략하게 소개하고, 다음의 소수 논문만을 간단히 살펴보도록 하겠다.
SRCNN
VDSR
SRGAN(SRRseNet)
EDSR, MDSR
1. SRCNN
Chao Dong et al, "Image Super-Resolution Using Deep Convolutional Networks", 2014 ECCV
Fig1. SRCNN architecture
SRCNN은 super-resolution 분야에 딥러닝을 최초로 적용한 논문이다. 방법은 보시다시피 매우 간단하다. Low-resolution image에 bicubic을 이용하여 HR 사이즈와 동일하게 키운 후 이미지의 size를 유지하며 convolution network를 3번 통과하여 이미지의 화질을 개선시킨다. 매우 간단한 방법임에도 불구하고 좋은 성능을 보인다.
2. VDSR
Kyoung Mu Lee et al, "Accurate Image Super-Resolution Using Very Deep Convolutional Networks", 2016 CVPR
Fig2. VDSR architecture
VDSR은 아주 deep 한 네트워크로 VGG-net에서 영감을 받았다고 한다. 20개의 레이어를 사용하였으며 계단식의 작은 필터들을 여러번 사용함으로써 이미지 전반적으로 contextual information을 잘 활용할 수 있었다고 한다. 또한 adjustable gradient clipping을 사용함으로써 104배의 큰 learning rate(SRCNN과 비교하였을 때)가 느린 수렴 속도를 보완해 주었다. 위 그림에서 마지막에 한번의 residual 이 들어감을 알 수 있는데, 이 여파인지 VDSR 이후의 super-resolution 논문들은 residual block을 적극 활용하고 있다.
3. SRResNet(SRGAN)
Christian Ledig et al, "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network", 2017 CVPR
Fig3. SRGAN architecture
지금까지 super-resolution의 accuracy나 speed면에서는 크게 성능이 좋아졌으나 high frequency를 갖는 texture detail들이 잘 살지 않는다는 단점이 있었다. SRGAN 논문에서는 GAN의 형식을 사용함으로써 texture를 보다 잘 살린다는 장점이 있다.
기존의 논문들은 MSE loss와 PSNR metric을 동시에 사용하여 이미지의 화질개선 성능을 평가했기에 PSNR 수치는 높으나 엣지가 선명하지 않은 blur된 이미지가 도출되었다면, 본 논문에서는 adversarial loss 와 content loss를 사용하는 perceptual loss function을 적용함으로써 사람이 보기에 더 좋아보이는 이미지를 만든다는 점에서 큰 차이가 있다. perceptual loss는 VGG network의 high-level-feature maps를 사용하였다.
위 그림에서도 확인 가능하듯 generator network에서 ResNet과 skip-connection을 적극 활용함으로써 time과 memory 절약에 좋은 성능을 보였다.
위 논문에서도 알 수 있듯, loss function과 metric은 이미지 개선에서 큰 차이를 불러 일으킨다. 기회가 된다면 지금까지 deep learning에 사용되는 loss function들(l1, l2, cross entropy loss, VGG loss, perceptual loss 등)과 metric(PSNR, SSIM 등)의 상관관계를 분석해보고 각 loss fuction들과 metric들이 가지는 장단점들에 대하여 정리해보는 포스팅을 진행해 보겠다.
4. EDSR, MDSR
Bee Lim et al, "Enhanced Deep Residual Networks for Single Image Super-Resolution", 2017 CVPRW
EDSR, MDSR 논문에서는 residual block에서 불필요한 요소들을 제거했다는 것이 큰 특징이다. 기존의 super-resolution 논문들은 MSE, L2 loss를 사용한 반면, 본 논문에서는 L1 loss를 사용하였다. 또한 기존의 논문들에서는 한번에 한 종류의 scale에 대하여 학습시켰다면, MDSR에서는 x2, x3, x4배율 모두 upscale이라는 맥락 아래에서 weight들을 공유할 수 있을 것이라 생각하여 다양한 배율을 동시에 학습하는 multi-scale deep super-resolution system을 도입하였다.
Fig4에서 볼 수 있듯, 본 논문에서는 residual module에 포함되어 있던 batch normalization을 제거하였다. BN layer에서 feature들을 normalize하기 때문에 네트워크 내의 유연성 즉, 개선 가능성을 억제한다고 보았기 때문이다. 실제로 이런 간단한 변경이 디테일을 살리는 부분에서 도움이 되었다고 한다. SRResNet과 비교하였을 때, BN layer를 제거함으로써 GPU memory를 약 40% 절약할 수 있었다고 한다.
Fig5의 EDSR architecture는 SRResNet의 baseline을 따랐으나, residual block 밖의 ReLU activation을 제거하였다는 점이 다르다. Fig6의 MDSR architecture는 parameter가 공유되는 중간의 16층 ResBlock과 scale specific하게 진행되는 앞, 뒤 module로 구성된다. 네트워크의 머리부분에 해당하는 pre-processing module은 5x5 kernel의 2개의 residual block으로 구성된다. 상대적으로 큰 kernel를 이용함으로써 scale-specific한 부분들을 잡아낼 수 있었다고 한다. 또한 마지막 부분의 upsampling module을 parallel하게 진행시킴으로써 x2, x3, x4의 결과를 각각 얻을 수 있다.
앞서 소개한 논문들 후에 super-resolution을 다루는 논문들이 많이 나왔다. 종류별로 잘 정리되어있는 자료를 찾아 첨부한다.
Fig7. super-resolution papers
2019년 9월 17일에 발행된 논문의 자료임으로 대강 2014-2018(2019초)의 논문들이 정리되어 있다고 생각하면 될 것 같다.
DICOM 이란 Digital Imaging and Communications in Medicine 으로 이 포스팅은 의료영상 이미지 중 CT 이미지 전처리에 대해 다루려고 한다.
.dcm(dicom)파일로 저장된 의료영상 이미지는 float array를 따로 빼내어 딥러닝에 사용한다.
float array를 따로 저장할 수 있는 확장자가 많지만 필자는 주로 tiff 파일로 저장하여 사용한다.
다이콤파일에서 픽셀 어레이만 뽑아서 가져온 후 쌓아서 저장하면 다 아닌가?
라고 생각할 수 있지만, 그게 다가 아니다!
dcm폴더 예시
3D영상의 경우, 위처럼 한 폴더 내에 여러개의 .dcm파일이 들어있다. 위 폴더에는 134개의 dcm파일이 들어있음을 볼 수 있다.
그런데, 파일 번호 순서대로 픽셀 어레이를 쌓으면 안된다. 번호 순서대로 쌓으면 위치순서가 엉망진창임을 확인할 수 있다. dcm파일을 읽은 후 InstanceNumber를 뽑아 sort한 후 쌓도록 하자.
from glob import glob
import os
import numpy as np
import pydicom
import skimage.external.tifffile import imsave, imread, imshow
dicom_dir = '/public_data/LIDC-IDRI/LIDC-IDRI-0001/01-01-2000-30178/3000566-03192'
dcm_files = glob(os.path.join(dicom_dir, '*.dcm'))
dcm_files = [pydicom.dcmread(s) for s in dcm_files]
dcm_files.sort(key = lambda x : int(x.InstanceNumber))
dsRef = dcm_files[0]
dcm 파일을 읽으면, 그 안에 많은 key들이 있다. dimension(key : Rows, Columns) 정보 뿐만 아니라, ct vendor사, pixel간 거리(key : PixelSpacing, SliceThickness), pixel array 등이 있으니 필요한 정보가 있으면 key를 뽑아본 후 정보를 확인해 보는 것도 좋은 방법이다.
"""
see all keys in dicom files
"""
print(dsRef)
print(dsRef.ImageType)
for key in dsRef.__dir__():
print(key)
print(key, dsRef.data_element(key))
"""
get dimension and thickness information from the dicom file
"""
dims = (len(dcm_files), int(dsRef.Rows), int(dsRef.Columns))
print('dims(z,x,y) : ', dims)
spacing = (float(dsRef.SliceThickness), float(dsRef.PixelSpacing[0]), float(dsRef.PixelSpacing[1]))
print('thickness(z,x,y) : ', spacing)
이제 dimension정보를 얻었으니 sort한 dicom_files를 토대로 pixel_array값을 불러오도록 하자.
recon_ct = np.zeros(dims, dtype = dsRef.pixel_array.dtype)
for i, df in enumerate(dicom_files):
try :
recon_ct[i,:,:] = df.pixel_array
except :
print(str(i+1).zfill(5) + '.dcm', '**pixel_array_shape Error')
HU(Hounsfield Unit)
CT영상을 처리하기 위해서는 Hounsfield Units(HU)이 무엇인지 알아야 한다. 이는 X선이 몸을 투과할 때 부위별 흡수정도를 표시한 지표로 CT number라고 부르기도 한다. 물을 0으로 고정하였을 때의 상대적인 흡수량이라고 생각하면 된다(물의 attenuation coefficient에 대한 상대적 비율 * 1000). 우리는 dicom 파일로부터 뽑은 픽셀 어레이를 우선 HU 단위로 정규화 해야한다. 이 때 필요한 것은 dcm파일의 Rescale Slope과 Rescale Intercept 이다.
CT이미지의 경우, 디스크에 저장되는 값과 메모리에 올라오는 값의 표현이 다르게 설정되어 있다. HU는 음수를 포함한 정수값이지만, CT이미지는 일반적으로 unsigned integer인 부호없는 정수로 저장되기 때문이다. 아래의 식은 메모리(output)와 디스크(stored value)에 저장되어 있는 픽셀값의 linear transformation 관계식이다.
HU에 맞는 값을 얻은 후, 무엇을 보고싶은지에 따라 알맞게 window width와 window level을 조정한다. 예를 들어, -1000~+400까지만 보고싶다면, upper bound = 400, lower bound = -1000으로 설정한 후, 0-1로 normalize하여 사용한다. 이렇게 새로 정의된 recon_ct 를 tiff file로 원하는 path에 맞춰 저장하면 된다.