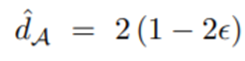이 논문은 기존의 CNN이 bias를 갖고 있다고 말하면서 시작된다. classification task에서 사람들은 보통 무늬나 텍스쳐보다는 모양을 위주로 보고 판단한다면, CNN은 모양, 즉 contents보다는 무늬나 texture를 위주로 보고 classification하는 bias가 존재한다고 한다.
이 논문의 contribution은 contents를 위주로 학습하는 네트워크와 style을 위주로 학습하는 네트워크를 구축함으로써 style bias 즉 domain bias를 줄인 CNN을 만들었다는 것에 있다.
input x와 random하게 뽑은 x'으로부터 contents biased network Gc는 x의 content, x'의 style을 가진 feature를 받아 contents만 보고 classification을 진행하게 되고, style biased network Gs는 x'의 random한 contents와 input x의 style이 합쳐져 style만 보고 classification을 하게 된다.
Content-biased Learning
contents biased network는 style을 blending시킴으로써 contents만 보고 판단하도록 만든다. z, z'은 feature extractor Gf의 output이며 각각 x, x'을 넣은 결과이다. z와 z'의 mean, std를 random한 숫자 alpha를 통해 interpolation하여 새로운 mean^, std^을 만든다. 그 후 z의 mean와 std를 mean^, std^로 변경시켜주어 contents는 동일하나 style이 달라진 feature로 만든다.
이 점에서 주의할 점은 이 논문에서는 feature의 style은 mean와 std라는 가정 하에 진행되고 있다는 것이다. style transfer, instance normalization과 같은 선행연구들을 보았을 때 mean과 std가 어느정도 style에 연관이 있다는 사실은 자명하나 mean과 std가 가장 좋은 파라미터라고 말할 수는 없다. feature의 correlation을 계산하는 gram matrice도 style을 나타내는 파라미터라고 볼 수 있다. 무엇이 가장 옵피멀한 방법인지는 모르겠다. 이부분에 대해서는 더욱 연구되어야 할 부분인 것 같다.
그 후 style이 randomization된 contents biased output에 대한 loss를 Gf, Gc에 update 한다.
Adversarial Style-biased Learning
위의 contents biased learning에서와는 달리 interpolation을 진행하지 않은 상태로 z의 mean과 std로 z'의 pdf를 변경시킨다. 이렇게 되면 z'의 random한 contents는 가지고 있는 상태로 style을 대변하는 z의 mean과 std가 합쳐진 상태가 된다.
z의 style만을 가지고 classification을 판단하는 위의 loss를 기반으로 Gs를 update해준다.
우리는 style에 bias가 적은 network를 만드는 것이 목적이기 때문에 style만을 보고 판단하는 Gs로부터 cross entropy가 maximize되는 방향으로 Gf를 업데이트 해준다. (yk대신 1/K를 곱해준 것의 의미) 이 때 Gf의 모든 parameter를 업데이트하는 것이 아닌 affine transformation parameter(batch normalization parameter)만을 업데이트한다.
Pseudo Code
Results
논문을 보면 다양한 관점에서 test가 진행되었다. 위의 test는 texture/Shape bias에 관한 실험으로, Gf에 업데이트되는 adversarial loss를 조절하는 adversarial weight를 높일수록 texture 학습은 낮아지고, shape 학습은 높아지는 경향성을 보였다. 또한 같은 class 내의 A-distance또한 줄어들었음을 확인했다.
Domain Generation 에 관련된 많은 dataset을 가지고 실험한 결과, AlexNet, ResNet18 backbone모두에서 sagnet의 training 방식을 사용했을 시 평균 정확도가 높아짐을 볼 수 있었다.
위 결과는 Unsupervised Domain Adaptation에 적용한 것으로 Office-Home dataset과 DomainNet dataset에서 모두 classification accuracy가 1-3정도 높아지는 것을 확인하였다.
먼저 cyclegan을 이용해 source domain을 target domain으로 domain adaptation을 진행하고 target domain으로 스타일이 바뀐 source data로 segmentation 네트워크를 학습하여 실제 target domain에서의 성능을 높이는 방법이다.
2. target domain으로 옮겨진 source data'을 이용하여 segmentation 네트워크 학습시키기 (deeplab)
이런 2 step domain adaptation은 사실 이전에도 여러번 소개가 되었다.
Dual Channel-wise Alignment Networks for Unsupervised Scene Adaptation(DCAN) 이나 cyCADA 논문도 위와 같은 형식이라고 알고 있다.
그런데 이렇게 2 step으로 네트워크를 학습시킬 때 발생하는 문제점이 있다. 첫번째 step에서 Image Generator의 성능이 떨어진다면, 두번째 step에서의 성능이 결코 좋을 수 없다는 것이다. 즉, segmentation network의 성능이 image generator의 성능에 의해 한계점을 지니게 된다.
본 논문에서는 위와 같은 한계점을 보완하는 방법을 제시한다.
Contribution
논문에 제시되어 있는 자신의 논문의 기여는 다음과 같다고 한다.
"""
1. Bidirectional Learning System, which is a closed-loop to learn the segmentation adaptation model and the image translation model and the image translation model alternatively
2. Self-supervised learning algorithm for the segmentation adaptation model, which incrementally align the source domain and the target domain at the feature level, based on the translated results
3. New Perceptual loss to the image-to-image translation, which supervised the translation by the segmentation adaptation model
"""
1. 2step을 개별적인 단계가 아닌 유기적으로 이어지게 (closed-loop) 만듦으로써 앞뒤 스텝의 단점을 상호 보완 가능하게끔 만들었으며,
2. 두번째 스텝에서 self-supervised learning algorithm을 추가하였고,
3. 첫번째 스탭에서 두번째 스텝 네트워크를 활용한 perceptual loss를 추가하여 segmentation adaptation model로부터 training에 필요한 정보를 얻었다고 한다.
Model
전체 네트워크는 위와 같다.
Image Translation Model을 통해 source data를 target domain으로 shift 한 후, 그 shift된 source data를 Segmentation Adaptation Model을 학습하여 결과를 얻는다. 그런데 Image Translation Model에서 Segmentation Adaptation Model 아웃풋을 이용한 loss인 perceptual loss가 추가된다. Segmentation Adaptation Model에서는 adversarial loss가 존재하고, 스스로 mask를 만들어 self-supervised learning을 진행한다고 하는데... 자세한 내용은 loss를 천천히 뜯어보면 알 수 있겠다.
Loss
loss들을 같이 보기 전, 기억해야할 notation은 다음과 같다.
source data = S
target data = T
translated source data by forward cyclegan = S'
translated target data by inverse cyclegan = T'
Image Translation Model (cyclegan generator) = F
cyclegan inverse generator = F-1
Segmentation Adaptation Model = M
첫번째 스텝인 image translation model로 cyclegan을 활용하였으며,
그 loss는
image translation model loss
이다. 람다 GAN은 1, 람다 recon은 10 을 사용했다고 한다.
하나하나 뜯어보자. 첫번째로 GAN loss이다.
image translation model loss - GAN loss
S'과 T의 domain을 구분하지 못하도록. 또는 S와 T'의 domain을 구분하지 못하도록 만드는 loss이다. discriminator는 S'을 0으로, T 를 1로 구분하도록 학습하였으니, 반대로 generator는 S'을 1로, T를 0으로 라벨하여 loss를 얻는 것을 볼 수 있다.
image translation model loss - Reconstruction loss
F를 통과하여 만들어진 S'을 다시 F-1 함수에 통과하였을 때, S로 되돌아오는지, reconstruction 되는지 확인하는 pixel-level loss이다. L1 loss를 사용하고 있다. cyclegan 논무에 따르면, 이 loss를 추가함으로써 generator F가 다시 되돌릴 수 있을 만큼만 이미지를 바꿔주어 이미지의 content를 보존할 수 있었다고 한다.
image translation model loss - perceptual loss
논문의 핵심 특징 중 하나인 perceptual loss이다. 두번째 step의 segmentation model과 연결시켜주는 고리이기도 하다. segmentation adaptation model M을 마치 perceptual loss의 VGG 네트워크처럼 활용하여 S와 S'의 perceptuality, 그리고 F-1(S')과 S의 perceptuality를 줄이는 방향으로 학습한다. 람다 per은 0.1, 람다 per_recon은 10이다. 이러한 perceptual loss를 추가함으로써 segmentation adaptation model M이 가지고 있는 domain bias를 image translation model에서 보완해 줄 수 있게 된다.
두번째 스텝인 segmentation adaptation model로 deeplab v2를 사용하였으며,
그 loss는 self-sueprvised loss의 유무로 두가지 종류가 존재한다.
segmentation adaptation model loss without self-supervised loss
segmentation adaptation model loss with self-supervised loss
람다adv는 0.001이다.
이번에도 하나하나 뜯어보자.
segmentation adaptation model loss - adversarial loss
먼저 위 논문의 큰 특징 중 하나인 adversarial loss이다. image translation model 뿐만이 아닌 segmentation model에도 adversarial loss를 추가함으로써 image translation model에서 미처 줄이지 못한 source와 target 사이의 거리를 줄이는 방향으로 보완해 준다.
segmentation adaptation model loss - segmentation loss
segmenatation model에서 항상 등장하는 cross entropy loss이다. domain shift 된 S'을 input으로 하여 얻은 M(S') 결과값과 segmentation label Ys 사이의 loss를 계산한다.
segmentation adaptation model loss - self-supervised segmentation loss
마지막으로 핵심 loss인 self-supervised segmentation loss이다. target data label이 주어지지 않았을 때, 스스로 라벨을 형성하여 unsupervised learning을 진행한다.
학습이 덜 된 네트워크에서 나온 결과값을 정답값이라고 가정한다는 것이 아이러닉하게 들릴 수도 있겠다. 그러나, segmentation task의 특징을 잘 생각해 보자. 도로를 segmentation한다고 했을 때, 도로의 정 중앙이 도로에 속한다는 것은 쉽게 알 수 있지만, 도로의 가장자리, 즉 나무 또는 보도와 가까운 pixel일수록 도로인지 아닌지 판단하는 것은 어려워진다. 즉, 같은 segmentation task에서도 pixel마다 쉽게 class를 판단 가능한지 아닌지 난이도의 차이가 존재하기에 확률의 차이가 존재하게 된다.
따라서 높은 확률로 판단 가능한 쉬운 pixel에 대해서 우리는 sudo label을 만들 수 있다. 몇퍼센트의 확률로 class를 확신하면 sudo label로 설정할 것이지에 대한 threshold는 0.9로 정했다고 한다. 이렇게 정해진 threshold로 우리는 target data에 대한 sudo label을 구할 수 있고, 이 sudo label을 논문에서는 mask라고 부른다. figure 3에서 예시로 주어진 mask를 살펴보면 구분선은 검정색(0)으로 구분하기 어려운 곳이기 때문에 sudo label을 형성하지 못한것을 볼 수 있고, 특정 class의 내부는 흰색(1)로 구분하기 쉬웠기 때문에 sudo label이 형성되었음을 볼 수 있다. 이렇게 정해진 sudo label에 대해서만 target segmentation loss를 구하여, training을 더욱 가속화한다.
Training Process
이렇게 정의된 2 step network를 구성하는 F,M model은 다음과 같은 프로세스로 training이 진행된다.
training process
먼저 일반 segmentation model과도 같은 M(0)를 학습시킨다. 위의 M을 training 하는 loss에서 adversarial loss와 self-supervised segmentation loss를 제외한 segmentation loss만을 활용한 것을 말한다.
이번 방학에는 domain adaptation 논문들을 정리하여 리뷰해 보려고 한다. 심심할 때 리눅스 쉘에서 자주 쓴 명령어도 정리해 기록해 보고자 한다.
지금 2020년도 기준으로 이번에 리뷰하는 [Domain Adversarial Training of Neural Networks] 논문은 어찌 보면 상당히 올드하다. 이보다 더 좋은 많은 알고리즘들이 쏟아져 나오고 있지만, 그럼에도 불구하고 Domain Adaptive에 가장 기본적인 성질을 담고 있으며, 이를 수식적으로 잘 설명한 논문이니 Domain Adaptation 카테고리에서 첫 번째로 리뷰해 본다.
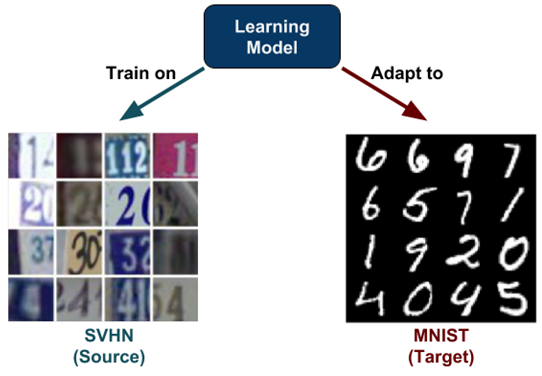
먼저 domain adaptation이란 무엇인지 간단히 짚고 넘어가 보자. domain adaptation이란 간단히 말해서 위와같이 잡지에서 찍은 것과 같은 SVHN 숫자 dataset에서 training 시킨 네트워크로 전혀 다른 style을 갖는 MNIST 숫자 dataset을 분류하는 데에 쓰고 싶을 때 두 domain의 간격을 줄여주는 방법이다. 우리는 이렇게 네트워크를 training 할 때 쓰인 dataset을 source dataset, 그 도메인을 source domain이라고 칭한다. 또한 source로 training 시킨 네트워크로 분류하고자 하는 test set을 target dataset이라고 하며, 그 도메인을 target domain이라고 한다.
간단한 문제에서는 source domain 하나, target domain 하나가 주어진다. 더 고차원적인 문제를 생각해 본다면, source에 한가지의 domain이 있는 것뿐만이 아닌 여러 가지의 다양한 domain이 source domain으로 주어질 수 있다. 위 그림처럼 같은 숫자를 담고 있지만 그 숫자의 굵기나 색깔, 배경, 폰트가 다름으로써 다양한 domain의 숫자 dataset이 주어질 수 있다. 우리는 이를 [multi source domain adaptation]이라고 부른다. target domain이 여러 가지인 경우도 마찬가지로 [multi target domain adaptation]이라고 부른다.
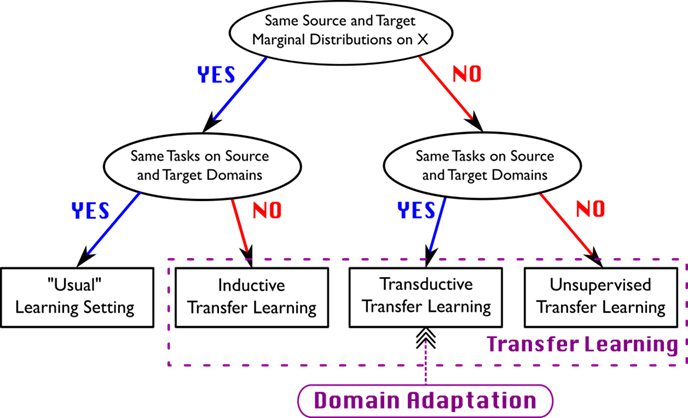
이런 domain adaptation은 transfer learning의 일종으로 분류된다. source와 target 데이터셋의 distribution이 다르지만, 두 도메인에 같은 task를 적용할 때 이를 Transductive Transfer Learning이라고 부르며, 이 해결 방식으로 Domain Adaptation이 제시되었다.
그럼 이제 진짜로 논문리뷰를 시작해 보겠다. 2020-07-25 기준으로 본 논문은 2000회에 육박하는 높은 인용수를 보인다.
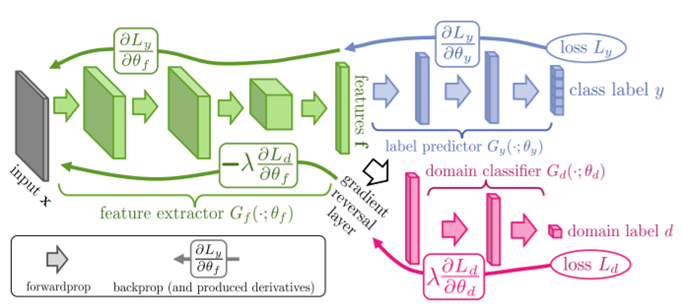
먼저 DANN(Domain Adversarial Neural Net)의 네트워크 구조를 보고 넘어가자. DANN은 classification에서 class label을 구분하는 task와 source와 target의 domain을 구분하는 두 task를 동시에 진행한다. 네트워크 앞부분은 서로 공유하며, 앞 네트워크에서 뽑은 feature로부터 class label을 구분하는 보라색 네트워크와 input으로 들어온 사진이 source인지 target인지 구분하는 분홍색 네트워크로 구성되어있다. 이때 우리의 목표는 앞의 feature extractor Gf가 최대한 source와 target에 동시에 포함되는, domain의 특성을 지우고 class 분류에만 쓰인 특징을 뽑게 하는 것이다. 이를 위하여 back propogation시 domain label을 구분하는 분홍색 네트워크에서 뽑힌 loss에 -람다를 곱해 feature extractor weight를 업데이트한다. 이렇게 되면
MInimize Training classification error
Maximize Training & test domain classification error
두 목적을 동시에 달성할 수 있게 된다.
위와 같은 방식으로 정말 domain간의 거리를 줄일 수 있는가?라는 의문이 들 수 있을 것이다. 위 논문에서는 실제로 줄어든다는 것을 수식적으로 증명한다.
그런데, 두 dataset의 domain 분포 거리를 줄이려면, 두 domain 거리를 측정할 수 있어야 할 것이다. 두 domain 사이의 거리를 측정하는 방식은 Domain Divergence를 측정함으로써 계산할 수 있다.
우리의 목적을 한번 더 말하자면, target domain error를 줄이는 것이다. target domain error는 source domain error + domain divergence로 upper bound를 정할 수 있다. 즉, source domain에서 classify를 잘하고, source domain과 target domain과의 거리가 가깝다면, target error가 작을 것이다.
Ben David는 domain divergence를 위와 같이 정의한다. 여러 domain classifier 이타를 원소로 하는 classifier 집합을 hypothesis class H 라고 정의했을 때, H-divergence란 두 도메인을 잘 구분하는 classifier를 얼마나 담을 수 있는지를 뜻하기에 도메인을 구분하는 능력을 칭한다. 실제로 거리의 개념은 아니지만 두 도메인 사이의 거리와 같은 말이라 생각해도 괜찮다.(말은 통한다)
H divergence는 'source domain을 1로 판단할 확률 - target domain을 1로 판단할 확률'이라고 정의되어 있다. 이해를 돕기 위해 간단히 예시를 들어보자면, classifier가 두 도메인을 구분하지 못할 때 위 식은 1/2 -1/2가 되어 0이 되며, 두 도메인을 잘 구분할 때 1-0 또는 0-1이 되어 그 절댓값은 1로 divergence가 커지게 된다.
그 밑에 나온 수식까지 함께 봐보자. 위의 식은 true divergence이며 밑의 식은 이를 정말로 구할 수 있게 modify한 empirical H-divergence이다. 위의 식으로부터 밑의 식을 얻기 위해서는
확률 Pr을 sigma * 1/n 으로 바꿔 계산 가능하게끔 만든다.
'source domain을 1로 판단할 확률' = '1 - source domain을 0으로 판단할 확률' 이므로 위의 식의 앞 Pr 부분을 치환해 준다.
이렇게 하면 empirical H-divergence를 구할 수 있다.
empirical H-divergence 식의 이해를 돕기 위해 좀 더 설명하자면, 먼저 I [ ]는 indicator function으로 true면 1을, false면 0을 뱉는다. min term 내부를 보면, domain classifier 이타가 domain을 잘 분리했을 때 1+1이 된다. 근데, 이 이타가 존재하는 공간은 symmetric hypothesis class이므로, 1+1이 존재하면 0+0도 존재하게 된다. (마치 100점 맞는 친구는 0점도 맞을 수 있다는 의미이다) 두 값중 min값이 선택되면 0+0이 선택되게 된다. 만약 domain classifier 이타가 domain을 잘 분리하지 못한다면 1/2+1/2가 된다.
따라서 min term은 잘 분리하면 할수록 0(0+0)에 가까운 숫자가 되고, 잘 구분하지 못할수록 1(1/2+1/2)에 가까워진다. 잘 구분하지 못할수록 숫자가 커지게 되니 이는 마치 loss 값과 같다고 할 수 있다. 그래서 이 min term은 domain classifier의 loss값으로 대체 가능하다.
min term은 domain classifier error인 입실론으로 대체되며, 이때의 H-divergence를 Proxy Distance, Proxy-A-distance(PAD)라고 부른다. 보통 이 domain classifier로 간단한 MLP나 linear SVM을 많이 사용한다.
직관적인 이해를 돕기위해 다시 예시를 들어보자면, domain loss가 작을 때, PAD는 커지게 되며, 이는 source와 target domain 거리가 멀어 구분이 쉽다는 것이다. 반면 domain loss가 클 때 PAD는 작아지게 되며, 이는 source와 target의 distribution이 비슷해 구분이 어렵다는 뜻으로 해석 가능하다.
지금까지의 과정을 되짚고 넘어가보자.
Target error <= source error + H-divergence
이며, H-divergence를 구하기 위해 empirical H-divergence를 구해봤다. 그런데 사실 true H-divergence와 empirical H-divergence는 완전히 동일할 수 없다.
true H-divergence의 upper bound가 empirical-H-divergence + H-complexity 로 measure 된다. 즉, 우리가 경험적으로 구한 empirical H-divergence에 그 classifier의 복잡도를 더한 값이 실제 H-divergence의 upper bound가 된다. 이는 overfitting과도 관련이 있는데, classifier가 train dataset에 맞춰 꼬불꼬불한 구분선을 갖게 된다면, 이는 train dataset에 overfitting 되어 valid dataset이나 test dataset에서 좋은 성능을 갖지 못한다. 이때 꼬불꼬불한 classifier는 complexity가 높다고 말할 수 있겠다. 이처럼 우리는 H의 complexity를 구해, 우리가 경험적으로 구한 H divergence가 실제로 잘 작동할 것이라는 것을 입증해야 한다.
를 수식으로 나타내면 위와 같다. 이타*는 domain을 잘 구분하는 classifier로 베타 >= inf(Rs+Rt) 식에 의해 베타는 source, target 모두에서 잘 작동하는 domain classifier 이타가 존재할 때 최소가 된다. 그런 classifier 이타가 H 안에 존재하려면(H는 classifier 이타의 집합이라고 위에 언급하였다!) H의 dimension은 충분히 커야한다. 그러나, complexity term이 존재하기에 H의 dimension은 한없이 커져서만도 안된다.
즉, 잘 구분하는 classifier 이타를 H에 포함할 수 있을 만큼 H의 complexity는 커야하지만(베타 값을 작게 하기 위하여), complexity가 너무 크다면, constant complexity의 값이 커져 결국 target error의 upper bound는 커져버리게 된다. 따라서 충분한 성능을 내는 classifier가 있어야 하나 이 classifier가 너무 복잡해서는 안 되겠다. 그래서 간단한 MLP나 SVM을 주로 쓰나 보다.
주절거리다 보니 본 논문의 핵심 아이디어는 대충 다..? 건들여 본 것 같다. 마지막으로 정리해보자면,
네트워크가 source domain에서 좋은 성능을 낼수록
source-target divergence가 작을수록
H set의 complexity가 적당히 클수록
target domain error를 minimize할 수 있다.
그럼 이만 논문 리뷰를 끝내고, 다음 포스팅부터는 2019-2020년도의 최근 논문 위주로 리뷰해 보도록 하겠다!